Александр Иванов 24/03/21
В XXI веке специалисты США и России по защите искусственного интеллекта идут разными путями, двигаясь к одной цели. Ранее всем была очевидна разница между "тоталитарным" автоматом Калашникова и другими "демократическими" образцами того же назначения. Сегодня ничего не изменилось. По-прежнему в России стараются все делать дешево и надежно, а в США могут себе позволить все самое дорогое, но не всегда самое надежное.
В предыдущей статье1 было показано, что применение обычного шифрования при защите персональных биометрических данных приводит к необходимости развертывания инфраструктуры: синтеза, распространения, хранения, применения, уничтожения криптографических ключей. Полноценное развертывание такой инфраструктуры – достаточно дорогое мероприятие. Некоторое удешевление может быть достигнуто за счет перспективного перехода к гомоморфному шифрованию.
Однако сегодня технология гомоморфного шифрования сырая (нет соответствующих стандартов и, соответственно, положительной практики их применения). Тем не менее решать проблему защиты приложений искусственного интеллекта необходимо.
Криптографы США, Канады и Евросоюза для этой цели с конца прошлого века активно продвигают так называемые нечеткие экстракторы2. Подавляющее большинство публикаций по этой тематике на английском языке, хотя встречаются и на русском3.
Как работают и зачем нужны зарубежные "нечеткие экстракторы"?
Принцип работы всех "нечетких экстракторов" иллюстрирует рис. 1. Этот тип средств защиты построен на том, что из "нечеткой биометрии" создают четкую гамму с большим числом в ней ошибок. Для их корректировки используют классические коды с большой избыточностью.
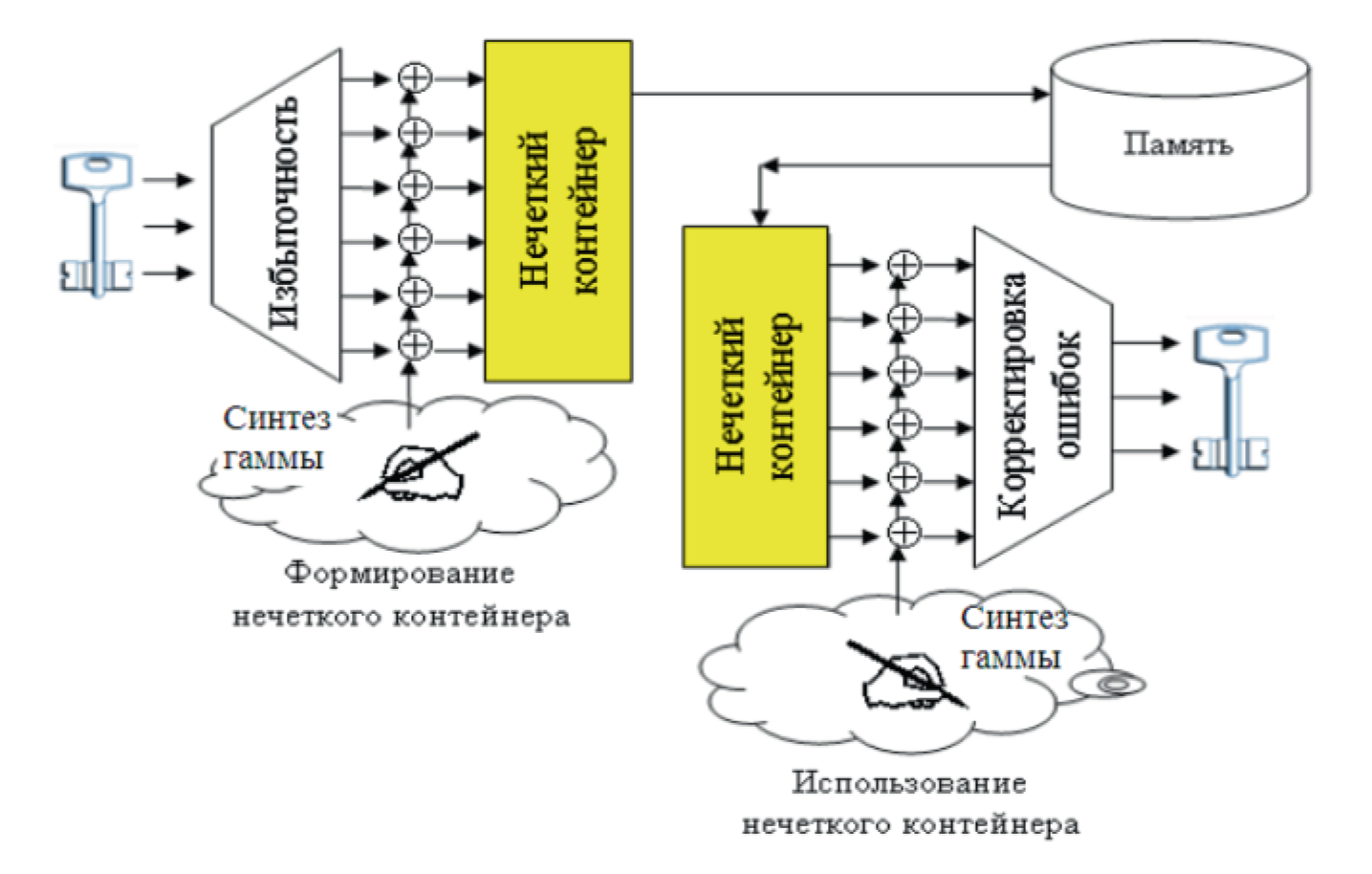
Рис. 1. Формирование и использование "нечетких контейнеров"
Как показано в левой части рис. 1, ключ шифрования "раздувают" избыточностью некоторого кода, способного обнаруживать и исправлять ошибки4. Далее избыточный самокорректирующийся код с ключом шифрования накрывают гаммой, созданной из биометрии. В итоге мы получаем "нечеткий контейнер" с информацией о ключе шифрования и информацией о биометрии пользователя. Судя по англоязычному консенсусу открытых публикаций, зарубежные криптографы считают вполне допустимым хранение в открытых пространствах подобных "нечетких контейнеров".
При использовании "нечетких контейнеров" вновь происходит предъявление биометрического образа. Из него снова синтезируется гамма, которая "почти" снимает первую гамму, полученную ранее при формировании "нечеткого контейнера". Естественно, что первая и вторая гаммы расходятся – они будут иметь ошибки в разных разрядах кода гаммы.
При использовании "нечетких контейнеров" происходит предъявление биометрического образа. Из него снова синтезируется гамма, которая "почти" снимает первую гамму, полученную ранее при формировании "нечеткого контейнера". Естественно, что первая и вторая гаммы расходятся – они будут иметь ошибки в разных разрядах кода гаммы. Эти ошибки устраняются избыточным самокорректирующимся кодом.
Эти ошибки устраняются избыточным самокорректирующимся кодом (правая нижняя часть рис. 1).
В первом теоретическом рассмотрении кажется, что подобная схема защиты вполне работоспособна, однако это далеко не так на практике. Все зависит от стабильности биометрических данных. Если речь идет о биометрии радужной оболочки глаза5, то эта технология работает вполне надежно с "нечеткими экстракторами". Совершенно иная ситуация возникает, когда "нечеткие экстракторы" применяются для биометрии рисунков отпечатков пальца6 или голосовых данных7. Стабильность и информативность биометрических образов этих технологий много ниже стабильности и информативности рисунков радужной оболочки глаза. Как итог, наблюдается большое число ошибок в первой и второй биометрических гаммах, приходится использовать самокорректирующиеся коды с очень большой избыточностью.
К сожалению, достоверных источников биометрических данных нет в открытом доступе. Это связано с рядом законодательных ограничений на сбор, хранение, использование персональных биометрических данных. Решена эта проблема только в России для динамики рукописных паролей. Для студентов, аспирантов, преподавателей русскоязычных университетов создано приложение "БиоНейроАвтограф"8. Биометрические данные, формируемые этим продуктом, общедоступны9, каждый пользователь может самостоятельно сформировать базы обучающих и тестовых выборок биометрических образов своим собственным почерком.
На рис. 2 приведена блок-схема применения данных среды моделирования "БиоНейроАвтограф" для моделирования работы "нечеткого экстрактора". Особенностью среды моделирования является то, что динамику воспроизведения любого рукописного образа манипулятором "мышь" или пером на чувствительном экране она переводит в 416 коэффициентов двухмерного преобразования Фурье, которые далее используются как контролируемые биометрические параметры.
При формировании защитной гаммы каждый биометрический параметр сравнивается с математическим ожиданием всех наблюдаемых биометрических параметров E(ν) ≈ 0. Если биометрический параметр положителен, то соответствующему разряду гаммы присваивается состояние "1". Для нулевых и отрицательных значений биометрического параметра в соответствующий разряд гаммы размещается состояние "0". Самые неустойчивые (нестабильные) разряды гаммы маскируются. В итоге мы получаем достаточно устойчивый самокорректирующийся код, содержащий порядка 30% ошибок. Чтобы поправить 30% ошибок, приходится использовать самокорректирующийся код с 30-кратной избыточностью. В итоге мы получаем ключ длиной 416/30 ≈ 14 бит, что соответствует примерно двум дополнительным случайным символам пароля доступа.
Таким образом, биометрия динамики рукописного пароля эквивалентна добавлению всего двух символов рукописного пароля, если мы будем ориентироваться на применение зарубежных "нечетких экстракторов".
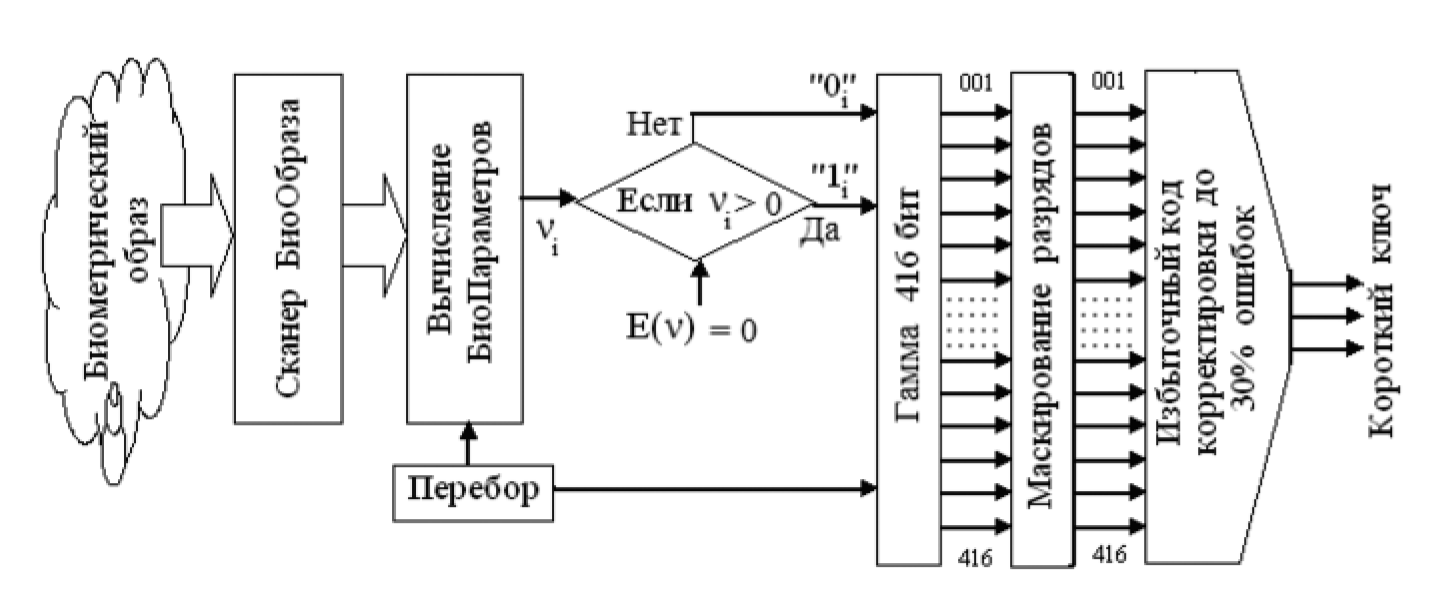 Рис. 2. Блок-схема защищенной обработки биометрических данных с использованием "нечетких экстракторов" (синтез и применение защитной гаммы 416 бит)
Рис. 2. Блок-схема защищенной обработки биометрических данных с использованием "нечетких экстракторов" (синтез и применение защитной гаммы 416 бит)
Высокая корректирующая способность сетей искусственных нейронов
Принципиальным недостатком всех классических кодов, способных обнаруживать и исправлять ошибки, является то, что они построены в рамках некоторой гипотезы. Например, это может быть гипотеза о равномерном распределении ошибок по коду. Естественно, что ошибки гаммы, выработанной из конкретного биометрического образа, не будут равномерно распределенными. Каждый биометрический образ будет иметь собственное распределение ошибок. Мы пока не умеем синтезировать коды, способные обнаруживать и исправлять ошибки с произвольным распределением их положения по коду.
Ситуация может быть изменена, если перед квантованием биометрических данных предварительно выполнить их обогащение. Для этой цели, например, могут быть использованы заранее обученные искусственные нейроны. По сути, это и есть тот национальный технологический тренд, которым руководствуются отечественные специалисты в XXI веке: использование сетей искусственных нейронов для обогащения сырых биометрических данных зафиксировано базовым отечественным стандартом ГОСТ Р 52633.010 в 2006 г.
Все типы искусственных нейронов способны обогащать биометрические данные за счет совместного использования вместо одного "хорошего" информативного входного параметра нескольких "плохих" низкоинформативных входных биометрических параметров. Все типы нейронов становятся способны объединять несколько "плохих" низкоинформативных биометрических параметров, превращая их в один выходной "хороший" параметр, только после их обучения на некоторой обучающей выборке.
В этом контексте принципиальным технологическим элементом является создание абсолютно устойчивых полностью автоматических алгоритмов обучения. Для искусственных нейронов с обогащением данных в многомерном линейном пространстве стандарт автоматического обучения ГОСТ Р 52633.511 в России введен в действие в 2011 г. Предположительно в 2023 г. может появиться второй национальный стандарт автоматического обучения сетей нейронов, осуществляющих обогащение биометрических данных в многомерных квадратичных пространствах12. Вполне возможно, что в более поздние сроки появятся и другие стандарты быстрого автоматического обучения искусственных нейронов с обогащением в экзотически деформированных многомерных пространствах. Например, в будущем возможно применение искусственных нейронов с обогащением данных в многомерных пространствах с полиномиально-ортогональной деформацией13.
С другой стороны, если нет полностью автоматического абсолютно устойчивого алгоритма обучения, то говорить о доверенном искусственном интеллекте нельзя. Участие в обучении человека-учителя всегда предполагает высокий уровень "доверия" к нему. Если в обучении искусственного интеллекта участвовал неизвестно кто, тогда и доверия к непонятно кем обученному искусственному интеллекту нет и не может быть.
Таким образом, наличие устойчивых алгоритмов обучения (устойчивость не утрачивается при любом числе входов у обучаемых нейронов) полностью снимает проблему преобразования биометрии в код любой длины. Для ее решения достаточно использовать нейросеть с необходимым числом нейронов. Так, для получения ключа длинной в 64 бита потребуется сеть из 64 нейронов. Для получения ключа длиной 256 бит нужна нейросеть, состоящая из 256 нейронов.
При этом число входов у нейронов выбирается исходя из качества обрабатываемых биометрических данных. Чем хуже качество входных данных, тем больше требуется входов у нейронов, обогащающих сырые входные данные. На рис. 3 приведена нейросеть, собранная из 256 нейронов, каждый из которых имеет четыре входа.
Следует отметить относительную простоту увеличения корректирующей способности сетей искусственных нейронов при наличии полностью автоматических алгоритмов обучения. Достаточно увеличить число входов у нейронов, например случайно подключив их к биометрическим данным, и запустить алгоритм автоматического обучения. Синтезировать столь простым способом новые классы кодов с обнаружением и исправлением ошибок нельзя. Именно по этой причине (быстрого автоматического обучения) сети искусственных нейронов корректируют ошибки намного эффективнее классических кодов с обнаружением и исправлением ошибок, неспособных к адаптации через обучение. Рис. 3. Нейросетевое преобразование относительно бедных (сырых) биометрических параметров в код длинного криптографического ключа без криптографических механизмов защиты
Рис. 3. Нейросетевое преобразование относительно бедных (сырых) биометрических параметров в код длинного криптографического ключа без криптографических механизмов защиты
Отечественная техническая спецификация: защита таблиц обученной сети искусственных нейронов криптографическими механизмами
Как показано на рис. 1, "нечеткие экстракторы" защищены гаммированием данных, однако все действительно стойкие криптографические алгоритмы защищают данные одновременно и гаммированием, и перемешиванием (размножением ошибки расшифровывания). В связи с этим обстоятельством при разработке первой в мировой практике технической спецификации защиты таблиц нейронной сети14 одновременно были использованы и гаммирование данных, и механизмы размножения ошибок.
Применение соответствующих криптографических механизмов защиты таблиц обученной нейронной сети иллюстрирует рис. 4.
При защите таблицы связей TCi и таблицы весовых коэффициентов TВi используется гамма, которая вырабатывается хешированием конкатенации состояния предыдущего нейрона сi-1 c таблицей связей предыдущего нейрона TCi-1.
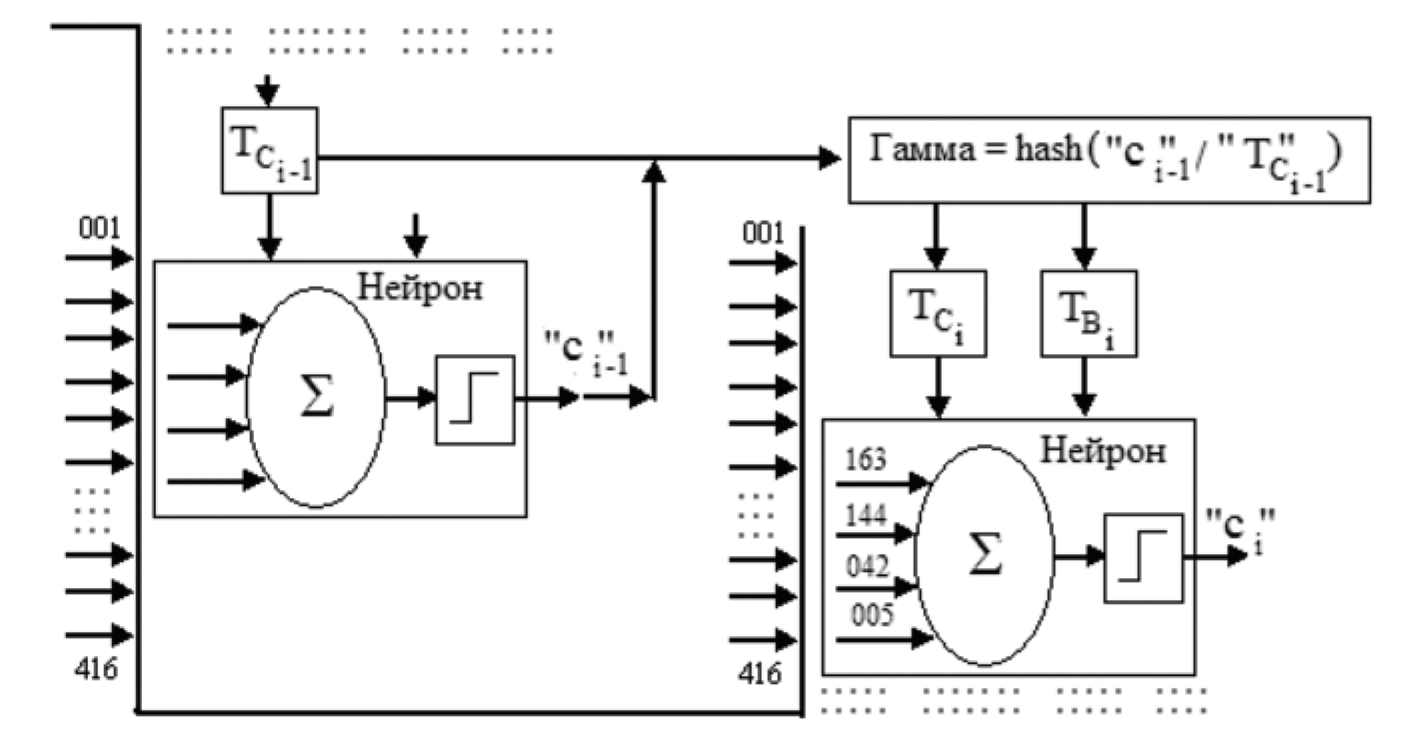 Рис. 4. Реализация механизмов защиты гаммированием таблиц и размножением ошибок
Рис. 4. Реализация механизмов защиты гаммированием таблиц и размножением ошибок
Это одновременно обеспечивает и синтез защищающей гаммы, и работу механизма размножения ошибок. Когда создается защищенный контейнер с накрытыми гаммами таблицами нейронов, вычисления не создают проблем, так как все данные известны.
При использовании защищенного нейросетевого контейнера вопросов с обработкой биометрического образа "свой" не возникает.
Вычисления повторяют выходные кодовые состояния всех нейронов и все гаммы, верно восстанавливающие таблицы каждого следующего нейрона.
Положение кардинально меняется, если защищенным нейросетевым контейнером злоумышленник пытается преобразовывать образ "чужой". Выходные коды нейронов не повторяют использованную при шифровании комбинацию. Вырабатываемые гаммы уже не повторяют те гаммы, которыми были накрыты таблицы нейронов. Злоумышленник, предъявивший образ "чужой", не имеет возможности получить данные о том, насколько предъявленный образ похож на образ "свой".
Рассматриваемый механизм защиты принципиально отличается от механизмов криптографической защиты "нечетких экстракторов". Во-первых, ключ запуска криптографических механизмов может быть длинным, во-вторых, для защиты используется не только гаммирование, но и перемешивание данных (хеширование).
Все это позволяет утверждать, что разработанная в России техническая спецификация применения криптографических механизмов для защиты таблиц сетей искусственных нейронов много сильнее зарубежных "нечетких экстракторов".
2 Juels A ., Wattenberg M. A Fuzzy Commitment Scheme // Proc. ACM Conf. Computer and Communications Security, Singapore – November 01–04, 1999. P. 28–36.
3 Чморра А.Л. Маскировка ключа с помощью биометрии // Проблемы передачи информации. 2011. № 2 (47). С. 128–143.
4 Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования. М.: Техносфера, 2007. 320 с.
5 Feng Hao, Ross Anderson, and John Daugman. Cr ypto with Biometrics Effectively, IEEE Transactions on Computers, Vol. 55, № 9, September 2006.
6 Ramírez-Ruiz J., Pfeiffer C., Nolazco-Flores J. Cryptographic Keys Generation Using Finger Codes // Advances in Artificial Intelligence – IBERAMIA-SBIA 2006 (LNCS 4140), 2006. P. 178–187.
7 F. Monrose, M. Reiter, Q. Li, S. Wetzel. Cryptographic Key Generation from Voice. In Proc. IEEE Symp. on Security and Privacy, Oakland, CA, USA, 14–16 May, 2001. P. 202–213.
8 Иванов А.И., Захаров О.С. Среда моделирования "БиоНейроАвтограф". Программный продукт создан лабораторией биометрических и нейросетевых технологий, размещен с 2009 г. на сайте АО "ПНИЭИ" http://пниэи.рф/activity/science/noc/bioneuroautograph.zip для свободного использования университетами России, Белоруссии, Казахстана.
9 Иванов А.И. Автоматическое обучение больших искусственных нейронных сетей в биометрических приложениях. Учебное пособие. Пенза, 2013. 30 с. http://пниэи.рф/activity/science/noc/tm_IvanovAI.pdf.
10 ГОСТ Р 52633.0–2006 "Защита информации. Техника защиты информации. Требования к средствам высоконадежной биометрической аутентификации".
11 ГОСТ Р 52633.5–2011 "Защита информации. Техника защиты информации. Автоматическое обучение нейросетевых преобразователей биометрия-код доступа".
12 Малыгина, Е. А. Биометрико-нейросетевая аутентификация: перспективы применения сетей квадратичных нейронов с многоуровневым квантованием биометрических данных. Препринт. Пенза: Изд-во ПГУ, 2020. 114 с. ISBN 978-5-907262-88-1.
13 Иванов А.И., Куприянов Е.Н. Защита искусственного интеллекта: ортогонализация статистико-нейросетевого анализа малых выборок биометрических данных. Препринт. Пенза: изд-во ПГУ, 2020 г. 72 с. ISBN 978-5-907262-72-0.
14 Техническая спецификация "Системы обработки информации. Криптографическая защита информации. "Защита нейросетевых биометрических контейнеров с использованием криптографических алгоритмов" принята 19.11.2020 г. на XXV заседании технического комитета № 26.
Подписаться на новости
Кибербезопасность предприятия и защита инфраструктуры, информационных систем, данных и приложений от современных угроз

Технологии защиты периметра и комплексная безопасность объектов промышленности, нефтегазового сектора и электроэнергетики
Пожарная безопасность и минимизация ущерба от возгораний жилых зданий и объектов коммерческой недвижимости

Поделитесь вашими идеями