Александр Иванов, Людмила Лекарь 18/10/23
Сегодня испытательным лабораториям недружественных стран доверять уже нельзя. Необходимы свои отечественные средства тестирования качества распознавания лиц, обеспечиваемого тем или иным коммерческим продуктом.
-1.png?width=709&height=410&name=%D1%80%D0%B8%D1%811%20(19)-1.png)
Ведущие зарубежные университеты и испытательная лаборатория NIST – National Institute of Standards and Technology (США) готовы осуществить тестирование нейронных сетей, распознающих лица людей. Однако сегодня доверенное тестирование приложений искусственного интеллекта (ИИ) должно быть выполнено именно в нашей стране, доверенной испытательной лабораторией на доверенной базе тестовых биометрических образов. Когда речь идет о распознавании образов лиц людей, должны использоваться реальные базы, полученные не в идеальных социальных сетях, а c реально работающих видеокамер охранной системы или от системы наблюдения с видеофиксацией. Нужен открытый код тестирования, соответствующий требованиям отечественных стандартов.
Какие образы лиц, какого качества, каких людей, в каких условиях они получены, каковы их объемы, – определять все это является прерогативой силовых структур, решающих проблемы защиты прав законопослушных граждан. Любой коммерсант России хочет поставлять свои продукты органам государственной власти, но вопрос в том, насколько тот или иной коммерческий продукт является качественным.

Почему нужны отечественные тестировщики ИИ
Распознавание лиц с использованием многослойных сетей искусственных нейронов давно уже стало промышленной технологией широкого применения. Один из отечественных лидеров в этой сфере – фирма NtehLab, которая в декабре 2021 г. прошла тестирование в испытательной лаборатории NIST (США) и, видимо, имеет на свой продукт-2021 зарубежный сертификат. Насколько потребитель из России может доверять сертификату NIST – вопрос открытый. Основой доверия к результатам тестирования является доверие не только к тестору, но и к базам биометрических образов, на которых было выполнено тестирование. Испытательная лаборатория NIST и аналогичные лаборатории иных зарубежных университетов не предоставляют доступ к своим тестовым базам. Какие у них тестовые базы, никто не знает.
Если тестовые базы имеют изображения "хорошего" качества, то и результат тестирования улучшится. Верно и обратное: рост в тестовой базе количества "плохих" изображений должен приводить к ухудшению определяемых вероятностных характеристик.
Вывод напрашивается сам собой: "спасение утопающих – дело рук самих утопающих". Нет смысла ждать милости от NIST и испытательных лабораторий других зарубежных университетов. Целесообразно привлекать к созданию испытательных лабораторий отечественных исполнителей, которым доверяет тот или иной потребитель технологии нейросетевого распознавания лиц.
Задача создания открытого программного обеспечения под тестирование не является сложной. Она вполне посильна кооперации промышленных организаций, которые договорились о протоколах тестирования. Национальный стандарт (например, стандарт технического комитета № 164 "искусственный интеллект") как раз и является некоторым компромиссом и чередой взаимных уступок производителей. главное, чтобы код средства тестирования был открытым (общедоступным).
Сказанное поясним рис. 1. Обычно программный продукт того или иного производителя строится на поиске лиц в видеокадре. В левой части рисунка приводится найденное в кадре лицо. Обнаруженный фрагмент с лицом приводится, например, к изображению 64х64 пк. Каждый пиксель является вектором входных данных для сверточной многослойной нейронной сети [1, 2]. условная сверточная нейросеть отображена в правой части рис. 1.
-1.png?width=947&height=525&name=%D0%A0%D0%98%D0%A11%20(20)-1.png) Рис. 1. Основа технологии применения многослойных нейронных сетей, заранее обученных свертывать длинный вектор входных сырых данных в вектор меньшей размерности – обогащенных выходных данных
Рис. 1. Основа технологии применения многослойных нейронных сетей, заранее обученных свертывать длинный вектор входных сырых данных в вектор меньшей размерности – обогащенных выходных данных
Основная задача любых нейронных сетей – это обогащение входных сырых данных. Нейросеть в правой части рис. 1 заранее обучена свертывать вектор сырых входных биометрических данных длиной в 4 096 пк в более короткий вектор из 256 биометрических параметров лица человека.
Обучение нейросети выполняется примерно на 20 примерах образа "свой" (20 разных изображений лица одного и того же человека). На 20 примерах удается вычислить математическое ожидание каждого из 256 контролируемых биометрических параметров, а также их стандартное отклонение. в этих условиях как основа, решающее правило для каждого примера, может быть использовано расстояние Евклида:
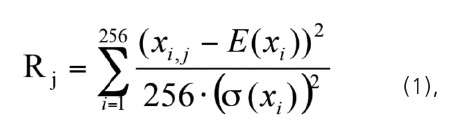
где E(.) – оператор вычисления математического; σ(.) – оператор вычисления стандартного отклонения, j – номер примера в обучающей выборке.
Само решающее правило сводится к выбору допустимых порогов изменения расстояний (1). Обычно пороги выбирают таким образом, чтобы все примеры в обучающей выборке "свой" принимались.
Описанная выше технология не является экзотикой, это фрагмент машинного обучения. Под задачу оценки качества машинного обучения уже существует международный стандарт, который в ближайшее время будет гармонизован и введен в действие на территории России [3].
Решение проблемы обеспечения конфиденциальности содержания "рабочих" и "тестовых" баз биометрических образов
Отметим, что открытый код средства тестирования связан с тестируемым коммерческим продуктом только через длину вектора выходных данных сверточной нейросети. То есть от создателя коммерческого продукта потребуется добавить в тестируемую версию его продукта несколько дополнительных строк кода. Эти строки должны формировать для средства тестирования файл со значениями выходных векторов для 20 примеров образа лица человека. Доработка программного обеспечения под внешнее независимое тестирование минимальна. Для тестирования продукта его исходный код не нужен (полностью сохраняются авторские права производителя на код его продукта), если сертификация касается только обеспечиваемых приложением вероятностей ошибок первого и второго рода.
При наличии тестового программного обеспечения с открытым кодом сама тестовая база может быть любой, потребитель имеет возможность формировать ее сам, одновременно обеспечивая ее конфиденциальность. Разработчики открытого кода тестового программного обеспечения должны пользоваться своей тестовой базой, с которой они вольны поступать как угодно. Разработчики могут как сохранить, так и уничтожить после отладки продукта собственную отладочную базу лиц.
При такой постановке задачи потребитель программного продукта получает возможность выполнять самостоятельно тестирование качества всех предлагаемых ему коммерческих решений. При этом он сможет использовать свои собственные "рабочие" базы, по которым в будущем должен будет выполняться поиск того или иного биометрического образа. Нет необходимости передавать уже имеющиеся у потребителя "рабочие" базы сторонним тесторам. В ряде случаев обеспечение конфиденциальности биометрических образов является принципиально важным, например сохранение конфиденциальности базы лиц людей, уже когда-то преступивших закон, когда-то находившихся под следствием и отбывших наказание за содеянное.

Решение проблемы увеличения объема тестовых баз морфингом дополнительных образов (ГОСТ Р 52633.2)
Обычно стремятся к тому, чтобы объем тестовой базы был примерно в 30 раз больше, чем ожидаемая вероятностная характеристика ошибок второго рода (ложное принятие образа "чужой" как образа "свой"). Например, если для некоторого коммерческого продукта заявлена вероятность ошибок второго рода P2 ≈ 0,005 (доверительная вероятность – 0,995), то для проверки этого заявления потребуется тестовая база лиц "чужой" объемом не менее 60 тыс. тестовых биометрических образов [4].
Очевидно, что NIST (опираясь на госбюджетное финансирование США) всегда сможет заранее сформировать тестовую базу любого объема под заявленные достаточно высокие вероятностные характеристики коммерческих продуктов. Проблема высокой стоимости формирования больших тестовых баз биометрических образов известна давно, именно из-за нее руководство обычных производителей не создает собственные испытательные лаборатории качества коммерческих продуктов нейросетевого распознавания образов.
Такая проблема стоит для всех зарубежных университетов и производителей, кроме российских и белорусских. В 2010 г. принят национальный стандарт России ГОСТ Р 52633.2 [5], регламентирующий формирование синтетических векторов образов-потомков, полученных из векторов реальных образов-родителей. Общий подход к расширению тестовой базы иллюстрируется рис. 2.
.png?width=951&height=543&name=%D0%A0%D0%98%D0%A12%20(11).png) Рис. 2. Морфинг – размножение реальных биометрических образов лиц людей (образов-родителей) синтетическими биометрическими образами–потомками
Рис. 2. Морфинг – размножение реальных биометрических образов лиц людей (образов-родителей) синтетическими биометрическими образами–потомками
Если руководствоваться требованиями отечественного стандарта [6] формирования баз биометрических образов, то каждый образ должен быть представлен 20 и более примерами. Это требование обусловлено тем, что на каждом образе тестовой базы мы должны иметь возможность обучить свою нейросеть, например опираясь на расстояние Евклида (1). Как результат вместо одного изображения лица человека в тестовой базе появляется 20 изображений обучающей выборки. На рис. 2 эта ситуация поясняется для лица-1 и лица-7 в форме двух облаков над ними, отображающих нестабильность (размытость) каждого биометрического образа.
Очевидным также является то, что каждому примеру образа "свой" сверточная нейронная сеть будет ставить в соответствие 20 коротких векторов обогащенных данных. При организации поиска и тестирования на компьютере нет смысла хранить реальные примеры изображений лица, вместо них удобнее хранить их короткие векторы уже обогащенных биометрических данных. Это обеспечивает существенное уменьшение объема требуемой памяти и, соответственно, ускорение тестирования [7, 8].
Следует отметить, что морфинг двух лиц – давно используемая вычислительная процедура. Обычно ее применяют художники. Для этой цели художник вручную задает одинаковые точки на лицах, а далее компьютер создает промежуточные состояния между двумя лицами. Формально каждый программный продукт при поиске лиц на изображении выделяет некоторые точки на лице (см. рис. 1), опираясь на которые может быть построен морфинг (мультик) промежуточных вариантов между двумя связываемыми между собой лицами.
В рассматриваемом нами случае нет необходимости в обычном морфинге, так как мы имеем короткие векторы обогащенных данных. В соответствии с ГОСТ Р 52633.2 [5] для скрещивания двух векторов от двух изображений двух разных лиц и получения векторов одного образа-потомка достаточно выполнить операцию усреднения одинаковых параметров. Последнее отображено третьим облаком векторов на рис. 2, для которого можно восстановить примеры, однако в этом нет необходимости.
Создать первоначальную тестовую базу из 1 тыс. лиц студентов (сотрудников) посильно для любого университета (предприятия). Если процедура получения синтетических векторов будет построена на получении одного образа-потомка от двух образов-родителей, то удастся увеличить тестовую базу до 0,5 млн образов. При получении от двух образов-родителей двух образов-потомков мы увеличиваем объем тестовой базы до 1 млн образов лиц людей. Этого вполне достаточно для организации при любом отечественном университете испытательной лаборатории. Такая лаборатория может занять ту же позицию, что и NIST, не предоставляя доступ сторонним пользователям к своей тестовой базе.
Доверенное тестирование приложений искусственного интеллекта (ИИ) сегодня должно быть выполнено именно в нашей стране, доверенной испытательной лабораторией на доверенной базе тестовых биометрических образов. Когда речь идет о распознавании образов лиц людей, должны использоваться реальные базы, полученные не в идеальных социальных сетях, а c реально работающих видеокамер охранной системы или от системы наблюдения с видеофиксацией. Нужен открытый код тестирования, соответствующий требованиям отечественных стандартов.
Проблема практически полного отсутствия информации о статистиках тестовых баз
Позволить себе почти ничего не сообщать о статистиках используемых тестовых баз реальных биометрических образов могут далеко не все.
То, что дозволено NIST, никому иному не позволено. Если развитие тестирования пойдет по пути создания множества испытательных лабораторий разных предприятий, то предприятиям придется сообщать о статистических характеристиках своих тестовых баз. не вдаваясь в содержание статистик, рискнем назвать только некоторые их параметры.
- Число естественных биометрических образов, собранных по ГОСТ Р 52633.1 [6].
- Число добавленных синтетических образов, созданных по ГОСТ Р 52633.2 [5].
- Средняя вероятность ошибок второго рода – P2 для среднестатистического образа лица по базе естественных образов.
- Вероятность ошибок второго рода для наихудших по стойкости 3% лиц по базе естественных биометрических образов.
- Вероятность ошибок второго рода для наилучших по стойкости 3% лиц по базе естественных биометрических образов.
Необходимость в опубликовании такого типа статистик позволяет заказчику тестирования ориентироваться на качество собранных в той или иной базе тестовых образов. Подобные характеристики не сложно вычислить, формально они должны быть заложены в открытом коде тестирования и стандарте по тестированию (если таковые будут созданы).
По крайней мере, опубликование даже этих статистических характеристик должно существенно ограничить возможные манипуляции со стороны испытательных лабораторий.
Почему необходим контроль не только за коммерческими продуктами проверки качества работы нейросетевых приложений, но и за испытательными лабораториями? Ответ на этот вопрос прост: необходимо исключить возможность злоупотреблений (субъективности) со стороны испытательных лабораторий. Если испытательная лаборатория ничего не говорит о статистиках своих тестовых баз и не предоставляет эти базы подавшему заявку на испытание, то возможны злоупотребления. Если лаборатория хочет улучшить статистики проверяемого продукта, то ей достаточно ухудшить стабильность биометрических характеристик тестовых баз. Верно и обратное: повышение стабильности биометрических параметров среднестатистического биометрического образа будет обязательно приводить к улучшению вероятностных характеристик проверяемого продукта.
Заключение
Авторы данной статьи уверены в том, что создание открытого кода для тестирования качества работы нейросетевых приложений является вполне посильной задачей для отечественного научно-технического сообщества, однако до того или параллельно с этим нужен отечественный стандарт. В свою очередь, появление подобного программного обеспечения даст реальную возможность любой отечественной структуре развернуть под своим контролем испытательные лаборатории без компрометации конкретно используемых тестовых баз лиц реальных людей или иных образов.
Задача разработки нейросетевых приложений искусственного интеллекта, включая его предварительное тестирование, и задача самостоятельного тестирования качества заказчиком работы того или иного коммерческого продукта должны быть разделены. При этом размер используемых тестовых баз реальных образов лиц не является технической проблемой. По крайней мере, это относится к России и Белоруссии, где действует стандарт ГОСТ Р 52633.2– 2010 [5].
Список литературы
- Николенко С., Кудрин А., Архангельская Е. Глубокое обучение. Погружение в мир нейронных сетей. СПб.: Издат. дом. "Питер", 2018.
- Аггарвал Чару. Нейронные сети и глубокое обучение. СПб.: Диалектика, 2020.
- ПНСТ 835–2023 (ISO/IEC TS 4213:2022) Гармонизованный проект национального стандарта ТК 164. "Искусственный интеллект. Оценка эффективности моделей и алгоритмов машинного обучения в задаче классификации".
- ГОСТ Р ИСО/МЭК 19795–1–2007 "Автоматическая идентификация. Идентификация биометрическая. Эксплуатационные испытания и протоколы испытаний в биометрии. Часть 1. Принципы и структура".
- ГОСТ Р 52633.2–2010 "Защита информации. Техника защиты информации. Требования к формированию синтетических биометрических образов, предназначенных для тестирования средств высоконадежной биометрической аутентификации".
- ГОСТ Р 52633.12009 "Защита информации. Техника защиты информации. Требования к формированию баз естественных биометрических образов, предназначенных для тестирования средств высоконадежной биометрической аутентификации".
- Майоров А.В. Оценка стойкости защищенных нейросетевых преобразователей биометрия-код с использованием больших баз синтетических биометрических образов // А.В. Майоров, С.А. Сомкин, А.П. Юнин, А.Ж. Акмаев // Известия высших учебных заведений. Поволжский регион. Технические науки. 2018. № 4. С. 65–74.
- Иванов А.И. Искусственный интеллект высокого доверия. Ускорение вычислений и экономия памяти при тестировании больших сетей искусственных нейронов на малых выборках. // Системы безопасности. 2020. № 5. С. 60–62.
Опубликовано в журнале "Системы безопасности" № 5/2023
Все статьи журнала "Системы безопасности"
доступны для скачивания в iMag >>
Фото: grodno24.com

Взрывозащита технологического оборудования: защита опасного производственного объекта

Средства коллективной работы и платформы для корпоративных коммуникаций в офисе
Умные парковки и автоматизация пропускного режима для ЖК и коммерческой недвижимости


Поделитесь вашими идеями